How to Design API Analytics Data Collection for High Volume APIs
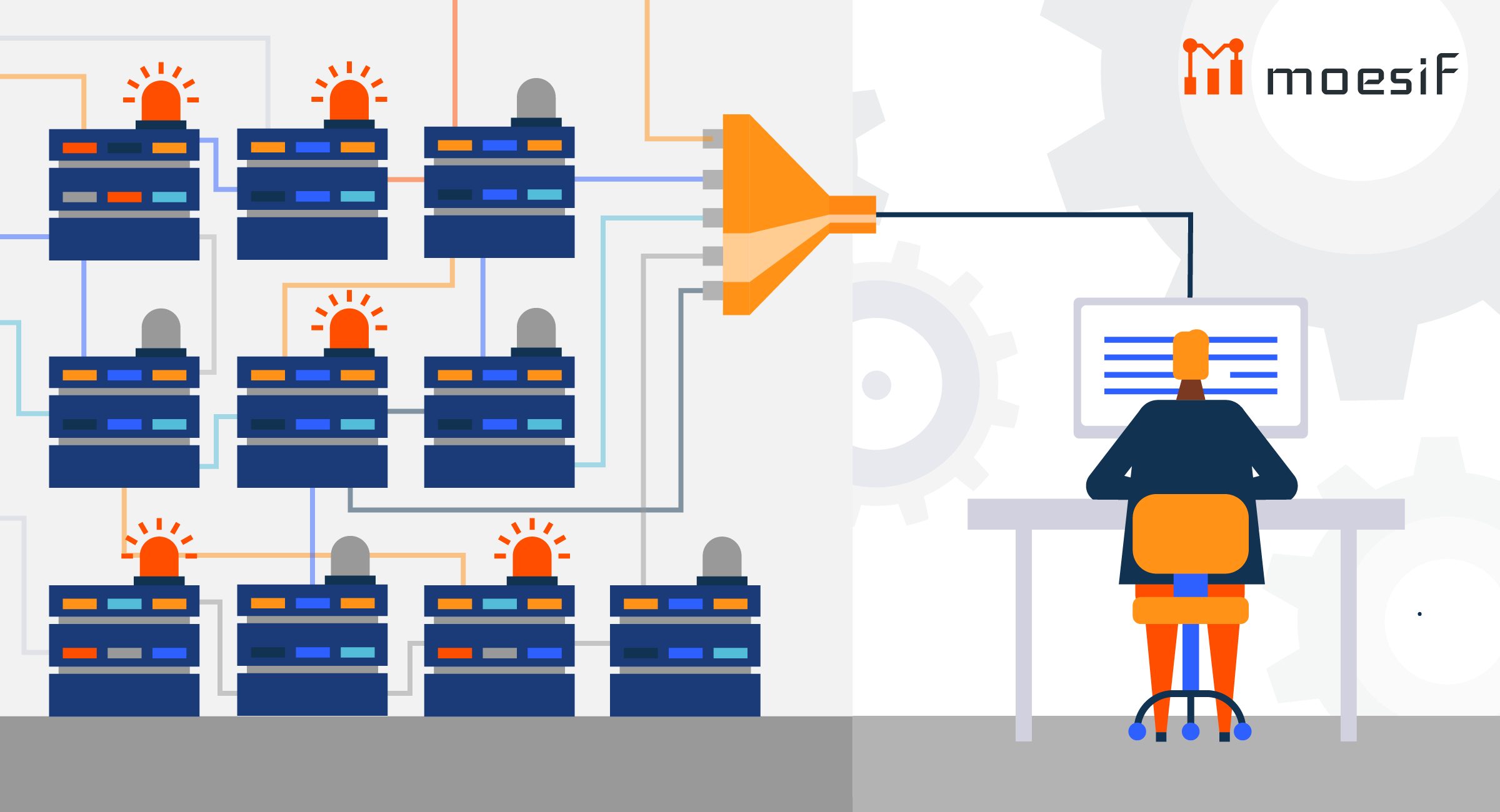
API Analytics platform are key for any platform company that wants to gain insights into their API and platform usage. These insights can be leveraged by product owners, growth teams, developer relations, and more to make more strategic decisions based on the raw health of your platform business rather than just gut feelings. However, many API platforms have a very high volume of API calls per day. This volume creates a set of unique challenges when designing an analytics system that scales without crippling their platform or having sticker shock when looking at their cloud vendor’s bill. This post goes into some of the inner workings of how we designs Moesif’s API analytics platform to handle companies with billions of API calls a day.
Agents/SDKs
Designing for scale starts with a well-designed agent to collect metrics from various applications and send to your analytics platform. Since the agent or SDK is embedded in your application, a poorly designed one could cripple your core services if your analytics service gets overloaded. In order to prevent this, your agent should have automatic fail safes and kill switches.
For starters, the agent should collect any metrics asynchronous from your core application code and should sit out-of-band, This way, even if your analytics service is down for extended periods of time, your application availability is not affected. Ensure any errors in processing metrics data are handled and not propagated back to the application itself. Since you’ll be collecting metrics asynchronously, you’ll want to leverage local queuing. This can be done in memory or to disc depending on the data consistency required. Keep in mind though, any resources that need to be allocated locally such as memory or disc required for a queue needs to be constrained. Otherwise, a queue could continue to grow without bounds if your analytics service goes down for an extended period of time eventually causing the process to run out of memory and crash. One way to solve this via fixed queue size and drop older events.
Dropping older events during a network disconnect means you sacrifice consistency for availability, a key pillar of Brewer’s CAP theorem which is usually referenced in when discussing distributed data stores, but is applicable here also. Queueing also enables you to batch events which reduces network overhead.
For more info, read Best practices for building SDKs for APIs
Sampling
If your API is processing billions of API calls a day, even with queueing and batching, you may quickly exceed your compute and and storage requirements. The compute cost to run such a system could easily be in the hundreds of thousands or millions of dollars a year. One way to reduce this pressure is via a smart sampling algorithm. While a rudimentary algorithm that consistently chooses a random percentage of events to log vs drop may work for the short term, this can heavily reduce the usefulness of your analytics system. This is because most products exhibit a power law curve when it comes to customer usage. Your top 20% of customers will create 80% of your traffic. This also means you have a long tail of customers that send very little traffic. Heavily sampling customers who send very little data in the first place can create distorted views of your customer journey.
One way to reduce this issue is by implementing a more intelligent sampling scheme. One way is sample on a per user or per API key basis. For example, any user who is a top 20% customer will have a sample rate of 10% whereas the rest of your customers will have a sample rate of 100% (i.e. capture all activity). This means you need a mechanism to propagate the sample rates to your agent.
Collection network
Regardless if your analytics service is accessible only from your own infrastructure only or is accessible from the intranet, you should have a system that can handle fail over in case one of the collection nodes goes down. A well designed network will leverage DNS-based load balancing across multiple data centers around the world such as AWS Route 53 or Azure Traffic Manager with a relatively short TTL. Within each data center, you can then leverage a proxy server like HAProxy, NGINX, AWS ELB to distribute traffic among your collector nodes. We at Moesif are heavy users of HAProxy to load balance within each data center and Azure’s Traffic Manager to load balance across different data centers. Your collector logic should be very light wight. It’s job should be only authentication, some lightweight input validation, and persisting to disc as quick as possible. This is where solutions like Kafka can be extremely useful.
Roll ups
Even if you sample, you may find that your storage costs are ever increasing and queries take exceedingly long time. Modern databases like Elasticsearch and Cassandra can hold hundreds of terabytes of data with their distributed architecture, yet you’ll run into increasingly long queries (or worse: out of memory errors) when you attempt to perform aggregations on these massive data sets. In addition, the storage requirements continue to increase. When it comes to analytics, you can choose the resolution you want to store the data. This can be the raw events as they come in, or rolled up into stories for all activity that happened in a particular period such as every minute or every hour. Rolling up a metric can drastically reduce storage requirements, but it sacrifices metric resolution. Many analytics systems have a tiered roll up strategy. For example, all data in last 7 days is stored down to the event resolution or on 5 second intervals. Older data greater than 7 days ago can be rolled up into hourly intervals. While even colder data that’s older than a year ago may be rolled up in daily intervals. It’s unlikely you’ll be looking at events down to the exact timestamp
Metric estimation
Sometimes you don’t need an exact count and can live within a certain level of error. Let’s take the example calculating weekly active API keys. Let’s say you have an ordered API log that contains the request time stamp and the API key used to access your API. A naive approach would be to create a map indexed by the weeks and then for each bucket, create a set that contains the unique keys for each bucket. An issue with this approach is you can quickly run out of memory if you have a large number of unique API keys (also known as high-cardinality). A different way to approach this would be leveraging a probabilistic data structure to infer or estimate the uniqueness of the set rather than directly counting. Example probabilistic data structures include HyperLogLog and Bloom Filters After all, you probably are interested in if there was 100 or 10,000 API keys active last week, but if your analytics system reported 101 instead of 100, your decision making wouldn’t differ. For this case, we can leverage HyperLogLog which approximates the number of unique values by estimating the number of leading zeros when the API keys are hashed together via a hashing algorithm. Accuracy is dependent on how many bits are allocated for this bit vector required to store the hashed values. Many modern databases for analytics like Druid and Elasticsearch have HyperLogLog built in, but it’s up to you to ensure your data can leverage them.


Related Articles

API Strategy
Leveraging AI For a Better API Strategy
Learn how to leverage AI to build and fortify your API strategy. Improve design, governance, documentation, and align APIs with business outcomes.
API Strategy
The 5 Best Mixpanel Alternatives of 2025
Learn about the best Mixpanel alternatives to determine the right analytics solution for your use case.

API Development
How to Leverage Moesif Effectively for API Observability
Effectively leverage Moesif for API observability through best practices for integration, event enrichment, custom actions, and engineering workflow integrat...
API Strategy
How to Build an Internal Chargeback Model for Your API and AI Usage Using Moesif
Use Moesif to implement internal chargebacks and enable precise API and AI cost attribution for better transparency and resource optimization.