GraphQL in Enterprise: What It Takes to Build, Deploy, and Monitor a New Enterprise GraphQL Service

New technologies always require some planning, changes, and experimentation before they merge into an enterprise stack. GraphQL adoption has been no exception to this. Companies like Airbnb, Netflix, Shopify, and other industry giants have all taken the leap to use this promising technology. In this blog, I will outline a few key considerations for creating your new service, deploying it, and monitoring the service. This assumes that you have a basic understanding of what GraphQL is, some of the key use cases, and awareness of some of the concerns in regards to adoption. With that in mind, let’s jump in.
GraphQL vs. REST
Before you being to build your GraphQL service, it’s important to consider the reigning approach for building Web APIs: REST. A common misconception about GraphQL is that it is a replacement for REST. Thinking of the technology in this light would be very wrong. Both GraphQL and REST can be very complimentary and most enterprises will use a mixture of both approaches.
When enterprises shifted from SOAP to REST, the transition was much easier to see and map out. Both contain strict contracts for request and response which meant that converting SOAP services over to RESTful services made a lot of sense. Some could even just be converted in a “like-for-like” fashion.
With GraphQL, it’s a tougher comparison and migration path compared to SOAP and REST. There are no GraphQL request and response contracts since they are defined when a query is executed. The caller of the GraphQL API sends whatever data is required to obtain the result they need and it is returned in the format that the caller has requested. This breaks the traditional pattern established with RESTful API design where there are very clearly defined request and response objects for an endpoint.
The greatest benefit of GraphQL over the rigidity of REST is that users can retrieve whatever data they need without having to create a new endpoint for each variation. This can definitely improve developer experience with your APIs and data. With REST, this has actually caused an API problem where it is sometimes easier to create a new endpoint than to modify an existing one and potentially break other applications using it. The result is a whole lot of APIs that are slightly varied and a whole lot more support effort to maintain them.
When making the decision of building your new API as GraphQL vs. REST, you’ll want to make sure that you require the flexibility of GraphQL, or maybe you just need the simplicity of a small RESTful API.
Do you really need GraphQL?
Establishing whether you really need GraphQL or not is a very important question to ask. With the adoption of GraphQL comes a learning curve for engineers and supports teams, as well as complexity.
Some examples of a great time to use GraphQL is when:
- You have a lot of relational data and you aren’t sure exactly how consumers will query it
- You’re currently experiencing issues with REST endpoint duplication and want to reduce the number of individual endpoints you have to support
- You have lots of services exposing the data you need and would like an easier way to query it without creating lots of new endpoints
- You want to subscribe to changes in data, possibly using GraphQL subscriptions as a solution
REST may be better in situations where:
- You’re application only requires simple, pre-defined CRUD operations
- You are adding to an existing project that is already efficiently using a RESTful approach
- You require firm rate-limiting and quota management
- You require heavy caching or need to design for throughput
Of course, there are many different arguments for why you should use either technology in lieu of the other. Above are just a few considerations for each approach.
If you want to expose your data so that multiple applications can use it exactly as they see fit, GraphQL is a great solution. If you need a simple CRUD interface than others, simpler solutions may be a better choice.
Options for building a new GraphQL service
GraphQL services can essentially fit into the familiar “build vs. buy” dilemma. The original and most flexible way to build a GraphQL service is to select a language and framework, then build “from scratch”. Lots of frameworks exist in almost every language out there. GraphQL.org has a comprehensive list of all the languages and frameworks that support GraphQL.
When building from the ground up with a framework you’ll have the most flexibility but also have the steepest learning curve. Your support teams will also need to come up to speed to know the intricacies of the code if an issue arises. The trade-off of high flexibility and customization comes with a price tag that is quite steep in terms of build time, learning the framework, and supporting this custom code once it hits production.
An alternative with a seemingly lower learning curve would be to build using a product that allows you to use existing infrastructure to create your GraphQL service. A few examples include:
- Hasura
- Connect your favorite databases and create a GraphQL API service automatically
- Fauna
- Create a database and a GraphQL API service from a single schema
- Tyk’s Universal Data Graph
- Use your existing RESTful APIs to create a new GraphQL API Service with no code required
- Mulesoft’s AnyPoint DataGraph
- Use the APIs you’ve already built to expose a new GraphQL service
Many of these solutions allow you to use existing infrastructure, services, and data to create a brand new GraphQL service. Almost all require no additional code, aside from customizations you may want to implement, which means the learning curve and build times are heavily decreased. Compared to building a “ground up” service, this approach offers a bit less flexibility but rewards users with very rapid time-to-market.
Don’t forget about frontend changes
Another part of bringing GraphQL into the enterprise is to also make changes to your frontend and any clients that will consume the API. In an existing frontend project, likely using RESTful endpoints currently, there can be a significant amount of work to get GraphQL integrated and working. Each RESTful call will need to be mapped into the equivalent GraphQL call and the returned data handled within the application. This may require in-depth knowledge of your GraphQL schema in order to map these operations.
The code changes alone can take a significant amount of time and should be budgeted for when planning a GraphQL conversion project. The frontend team will also need to be educated on GraphQL if they are unaware of how to leverage the technology. This will also include the addition of a frontend GraphQL client, such as Apollo Client, and learning how to use it to interact with your new GraphQL service. This obviously is less cumbersome when starting with GraphQL from the inception of the project.
A final consideration to be made is the amount of regression testing needed for the product or system once the GraphQL changes are in place. End-to-end testing needs to take place to ensure that the API is working as expected, along with any logic in the services which power the responses. This same testing approach must also be applied to the frontend UI experience to ensure that the app works as it did originally.
Managing common GraphQL Concerns
GraphQL, still in its infancy, wrestles with a few concerns which should be considered when choosing to use and implement it. Below we will review a few of the most common concerns to look out for while implementing GraphQL.
Security
A top concern for many adopters of GraphQL is the worries about vulnerabilities built into GraphQL. Although many seasoned GraphQL users are aware of them, it’s very easy to forget about many of the attack vectors that are exposed through a GraphQL service. These include SQL injection, query traversal attacks, and many others which are easy to execute and hard to spot. WunderGraph has a complete breakdown of many of the most important vulnerabilities to look out for in this post.
Caching
GraphQL is very well-known for its caching intricacies. Unlike REST responses, which are easily cached, GraphQL presents unique challenges. A good amount of the caching issues have been solved by individual solutions but it can be complex to implement and not all solutions holistically solve the issue. A great overview of all the facets of caching in GraphQL is available in this article.
Complexity
Implementing GraphQL can sometimes be more complex than solving a problem with a conventional RESTful approach. Sometimes GraphQL services become very complex to build and support even though the data they offer is simple in nature. It may also lead to consumers needing a more complex understanding of the underlying data structure and what fields are available. Having to write complex queries can also add to confusion for developers new to your GraphQL API. At the enterprise level, this could mean a lot of education around the services capabilities for existing consumers.
Rate limiting and Quotas
With a RESTful endpoint, it is relatively simple to enforce a rate limit and quota on a specific endpoint. GraphQL services are served through a single endpoint which makes this a bit tougher. You can enforce a rate limit and quota against the GraphQL endpoint but this leaves little flexibility and customization. The best way to enforce rate limiting and quotas is either limiting per field, or more commonly, by doing a GraphQL query cost calculation and allocating a specific amount of points per user. Shopify’s Engineering team did a great write-up on this a few years back. A tool like Moesif’s governance feature can meter and enforce quotas for specific GraphQL fields and operators.
Error handling
Handling errors in GraphQL is done a bit differently than it is with a RESTful service. With REST, error codes are returned back when something goes wrong within a call or transaction. It is very much an “all-or-nothing” transaction, either the call is successful or returns back one of a multitude of possible error responses. With GraphQL, even if a response contains errors or if certain fields were not able to be resolved, the response status will still show as successful. This means that error handling must be much more explicit than just looking at the HTTP response status code. The GraphQL spec itself even contains pretty vague guidance on how to format errors in a GraphQL response. Apollo GraphQL has a few tips on how to tackle this frustration in a previous post.
Deploying the GraphQL service
Deploying a GraphQL service, including the GraphQL server and the corresponding frontend GraphQL implementation, works the same way you would deploy a RESTful API service if you’re building it using a framework.
When it comes to many of the “bought” solutions like Hasura or Fauna, most of these are offered as a managed SaaS-style deployment. This means that deployments require minimal effort and configuration to get them up and running. Some of these solutions also offer a self-managed, on-premise solution as well, if needed. Obviously managing your own deployment and resources in a self-managed manner is going to take more effort and support resources.
The team in charge of deploying the solution should be aware of how to configure it and also, for “bought” GraphQL products, be aware of how to move logic and other dependencies from the development environment through to the production environment.
Monitoring the GraphQL service
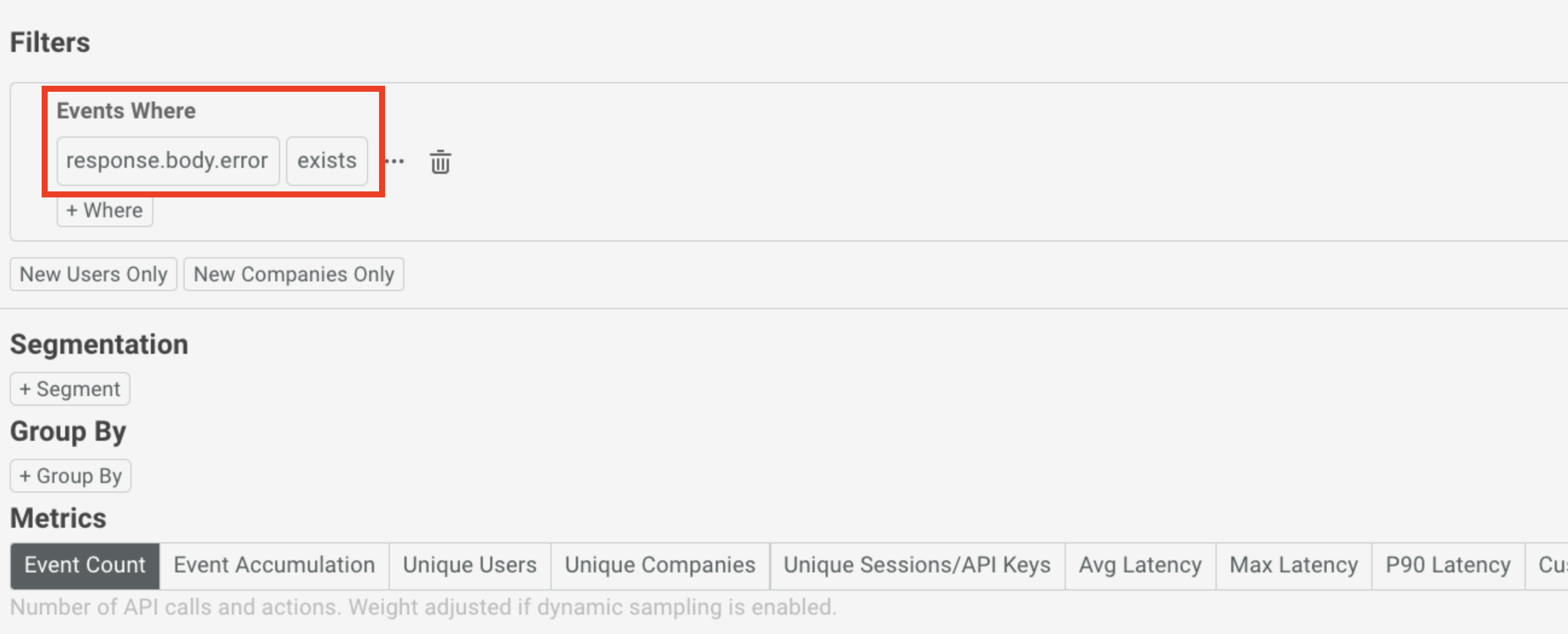
Once your GraphQL service is up and running in production, it’s important to monitor it for errors, usage, and adoption. Traditional APM vendors have trouble monitoring GraphQL since they look at only the URL and status code. However, GraphQL calls are usually to the same /graphql API endpoint and do not necessarily utilize the HTTP status codes. The best GraphQL monitoring tools provide flexibility to analyze specific operations and body fields. A solution like Moesif allows you to get alerted on the presence of specific body fields like response.body.error, which is a common error format for GraphQL APIs.
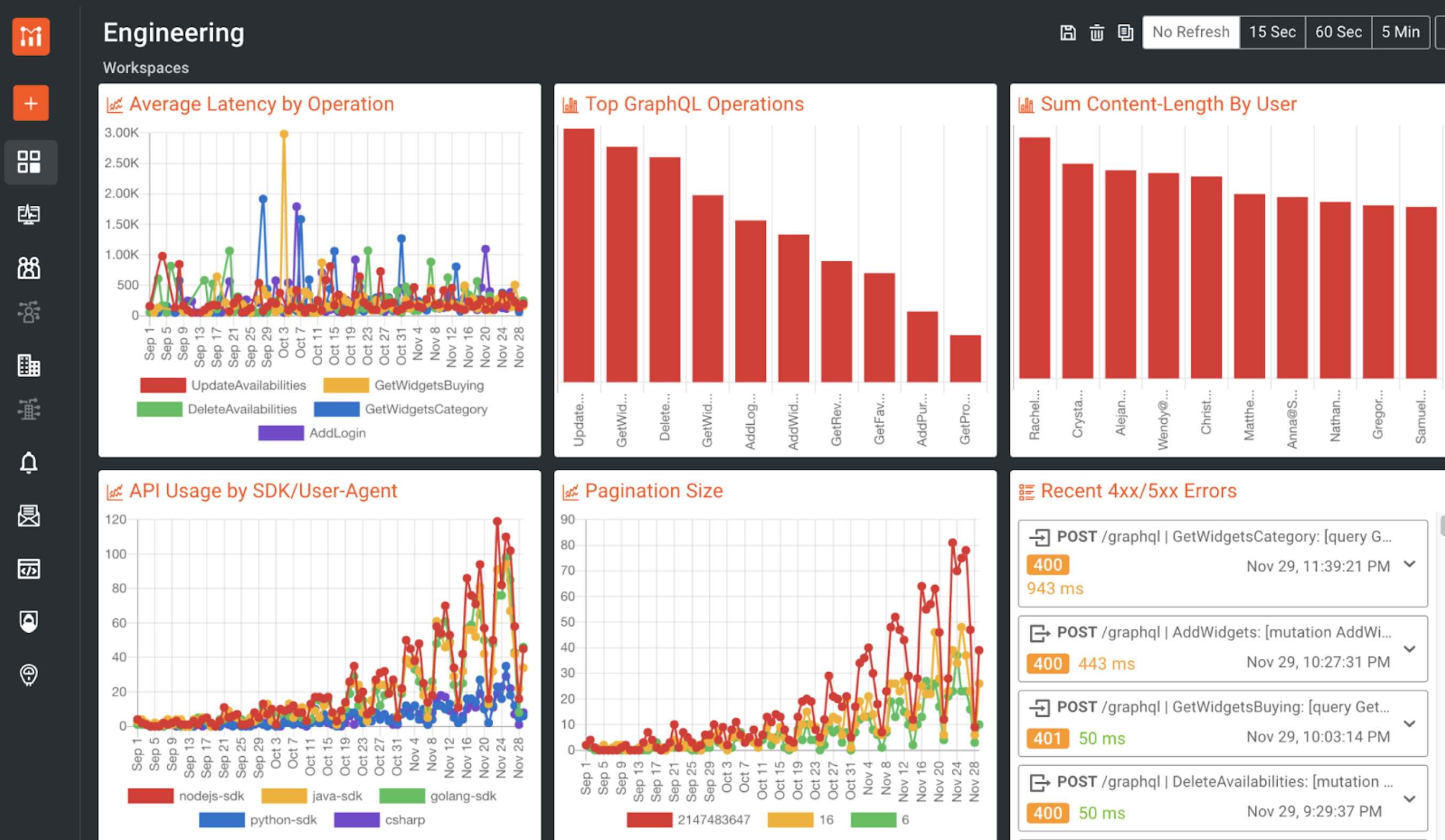
Moesif can also provide product insights into how your GraphQL APIs are accessed compared to your REST APIs. This enables you to track how the usage differs if you’re migrating from REST to GraphQL. This includes the ability for Moesif to track GraphQL operations, such as a GraphQL mutation, and filter based on specific fields so that you can see which are being used and how they are being used.
You can also use Moesif to create alerts for your team and automated emails to users based on usage. This can help with onboarding, feature adoption, and customer success efforts in a fully-automated fashion.
Considering GraphQL or already using GraphQL in your latest projects? Sign up today to check out Moesif’s GraphQL monitoring capabilities to make the transition to enterprise GraphQL as easy, secure, and successful as possible.

Related Articles

Podcasts
APIs Over IPAs 17: Aligning API Design to Business Outcomes with James Higginbotham, LaunchAny
In this episode, Derric chats with James Higginbotham, founder of LaunchAny, about designing successful API strategies that drive business value.

API Analytics and Monitoring
Gravitee + Moesif: Unlocking API Observability And Monetization
Learn how you can achieve API observability and API monetization by using Gravitee and Moesif together.
Podcasts
APIs Over IPAs 16: API-First Strategy for Banking Platforms with Dave Biesack, Apiture
In this episode, Derric Gilling talks with David Biesack, Chief API Officer at Apiture, about how his team built a customer-first digital banking platform by...

API Development
AI Application with Vercel and NextJs with Moesif for Analytics
Building AI Application with Next.js with Moesif for Analytics and monetization.
